
長崎旅行
長崎で開催された言語処理学会全国大会に参加しました(聴きに行くだけ)。その報告です。
出発前
背景
私は学生の頃から、人狼知能大会というものにほぼ毎年参加しています。人狼AIを作って戦わせるロボコンみたいなものです。
そのテーマセッションがNLP2025で開催されることになりました。当初は長崎遠いしなあとあまり乗り気ではなかったのですが、
- 人狼知能オンリー懇親会が開かれる
- LLM関係の発表が豊富で、業務にも大いに関係ありそう
- 人狼知能主催者の先生に学生時代に大変お世話になった
- 別の大学なのに学会参加費を出してくれたり
- 「人狼AIで世界2位を取ったことがある」エピソードは就活時に環境破壊級の強さだった(参加者5人中)
といったこともあり、腹をくくって行くことにしました。
目的
そんなわけで、今回の目的は以下のとおりです。
- 業務上の目的
- AI活用関連の知見を持ち帰る
- 最新のLLMやRAGに関する情報
- 企業での生成AI活用事例
- AI活用関連の知見を持ち帰る
- 個人的な目的
- 綺麗なものを探しに行こう
- 美味しいものをたくさん食べよう
DAY 1
ついに大会が始まった!
言語モデルの内部機序_解析と解釈 講義メモ要約
講義メモが長くなりすぎたのでLLMで要約させたものが以下。
- LLMはブラックボックスと言われるが実際はかなり解析可能
- 内部表現の解析・解釈方法:
- プローブ技術:特定の概念(感情、地理情報など)に対応するニューロンを特定
- スパースオートエンコーダー:複数概念が重なった表現を分解
- 因果的介入(Activation Patching):内部状態を操作して出力変化を観察
- パラメータ・モジュール出力の語彙との紐づけ
- 内部表現の特徴:
- 周期的概念(時間など)は周期構造として表現される
- 文脈参照のための特殊なヘッド(Retrieval heads)が存在
- Attentionは文頭・文末・区切り記号に偏る傾向がある
- 哲学的考察:
- なぜLLMは世界知識を獲得できるのか?
- プラトニック表現仮説:
- あらゆる表現はイデアの投影なので、言葉を通して世界を理解できる
- 集合的予測符号化仮説:
- LLMが世界と接地するためのセンサー/アクチュエータに人間がなっているから
- プラトニック表現仮説:
- 解釈手法の限界:局在化の仮定、人間概念との対応付けの妥当性
- なぜLLMは世界知識を獲得できるのか?

人工知能の哲学入門 講義メモ要約
同じくLLM要約。
- 第二次AIブームまでは哲学者とAI研究者の活発な議論があったが、90年代以降下火に。現在のAI進展により再検討が必要
- 古典的人工知能の限界:
- 知能を計算・アルゴリズムとして捉える考え方
- 現実世界の複雑さ、open-endedな課題、組み合わせ爆発・フレーム問題、例外処理などに対応できない
- 現代の人工知能(深層学習):
- データからの学習とニューラルネットワークの活用
- 特徴量設計不要、大規模DNNによる複雑関数の表現
- 入出力のベクトル表現を工夫することで様々な課題に応用可能
- 人工知能の哲学的問い:
- AIの限界は何か?DNNは実際に何をしているのか?
- 深層学習は人間の認知原理なのか?
- 現代AIの課題:
- 大量訓練データが存在しない領域への対応
- 汎用人工知能の実現可能性
- バイアス、透明性、AIアラインメントなどの倫理的・社会的問題
- 言語モデルに関する哲学的問い:
- LLMの状態空間は何を表現しているのか
- LLMは語と語の確率的関係以上の情報を表現しているか
- LLMの言語使用に関する3つの見方:
- 意味理解なしでは十全な言語使用は不可能
- LLMは人間と同じ言語使用メカニズムを持つ
- メカニズムは異なるが意味理解なしで十全な言語使用が可能
- 言語哲学との関連:
- 言語使用説(ウィトゲンシュタイン)では言語外使用が本質だが、LLMは言語内使用のみ
- LLMは新たな内在主義の可能性を示唆している?
0310-1630-オープニング-a会場
- セッション数、スポンサー数、参加者数すべて過去最多
- サステナブルな大会運営のため、大会スローガンは放棄
- より専門的な話は分科会でやってもらう前提で、参加者間の交流重視
- スポンサーは103団体
- ダイアモンド: 2
- プラチナ: 53
- ゴールド: 18
- シルバー: 30
スポンサーイブニング
1スポンサー20秒で103団体の一言コメント。すごい勢いだった。
話を聞きに行こうと思ったリスト
- Stockmark
- FLYWEEL
- オルツ(alt)
- マントラ株式会社
- 漫画の翻訳をしてるっぽい
- SpiralAI
- キャラクタAI / AItuber
- 朝日新聞
- めぐりズムをブースで頒布
その後、長崎の伝統芸能である龍(じゃ)踊りが披露された。これもまたすごい勢いで、迫力があった。
非公式懇親会
公式Slackには非公式懇親会チャンネルがあり、そこでたくさん募集がかかっていた。 公式懇親会は申込時にはもう満員で参加できなかった。せっかくなので非公式懇親会に参加することにした。
- 毎回開催されているが非公式の初日懇親会らしい
- ザ・グローバルビュー 長崎(NLP2025の会場から徒歩約5分)の最上階のレストラン
- ホテルWebサイト https://www.rio-hotels.co.jp/nagasaki/
- MAP https://maps.app.goo.gl/5FFxgZPkY7pp2S37A
- 社会人6000円、学生2000円
- バイキング料理のクオリティが高いし、とりあえず同席したテーブルの人たちが互いに初対面かつ良い人だったのでとても良かった
- 最上階なのに景色を見るのを完全に忘れていた
- 話した人
- スクエニ 狩野竜二さん
- Q3-11 ロールプレイングゲームの画面情報分析による選択可能テキストの抽出 の発表者
- 発表見に行きますよ〜的な話をした
- SpiralAI 石原稔也さん(たしか)
- 個人的にLLMを使って娘を作っているらしい(???)
- 発表とかしないので完全自腹で来たらしい
- スクエニ 狩野竜二さん
DAY 2
昨日は前座みたいなもので、2日目からセッションやポスター発表が始まる。
ちなみに、予稿はすべて以下からダウンロードできます。人によっては発表スライドを共有してくれているので、何か気になる発表があればお知らせください。

Q1-1 書き手の孤独感を予測できるか?
- 孤独感に関するいくつかの質問に対する回答文から、その人が主観的に孤独か否かを判定する
- 現状だとあまりできていないっぽし
- ダイレクトに孤独か聞くだけでなく、愛情とか社会的孤独とかについての質問の回答文を足すと精度が上がった
Q1-7 小説テキストに対する登場人物アノテーション
- 小説・日本語の話者推定
- 結構高い精度(9割くらい)で予測できた
A1-5 検索拡張生成が信頼度に及ぼす影響:医療分野における分析
- RAGによってLLMが出力する際の信頼度も向上するか?
- RAGをした場合としなかった場合で比較
- Lost in the middle問題: 長文脈で中間のコンテクストが消失する を回避するため、検索結果は複数回挿入したりもした
- 細く設定を変えて書類を取得する
- 完全に答え
- 1つ答え、2つ無関係
- 全部無関係
- 評価
- ECE 期待較正誤差: 自身のないものはちゃんと間違え、自身のあるものはちゃんと答えられたか
- ACE 適応、、 : ↑を補正したもの
- ACC
- RAGをしなかった場合に比べ、した場合はどうなる?
- モデルごとに違うし指標ごとに違ってる
- Llama3.1ではやや改善、Phi-3.5では悪化
- 検索結果が良質・悪質だとどうなる?
- これも同じく、評価が難しい。モデルに依存して挙動が異なる
- 結論:
- 精度が上がる際は信頼度は悪化し、精度が下がる際は信頼度が向上する
- モデルは慎重に選ぼう
A2-1 大規模言語モデルにおける複数の指示追従成功率を個々の指示追従成功率から推定する
- 複数の指示を同時に守る性能について調査するベンチマークを2つ作成し、モデルの性能悪化の傾向を調査
- 指示をN個与えたら、N個全て守り切るのはどれくらいの成功確率か?

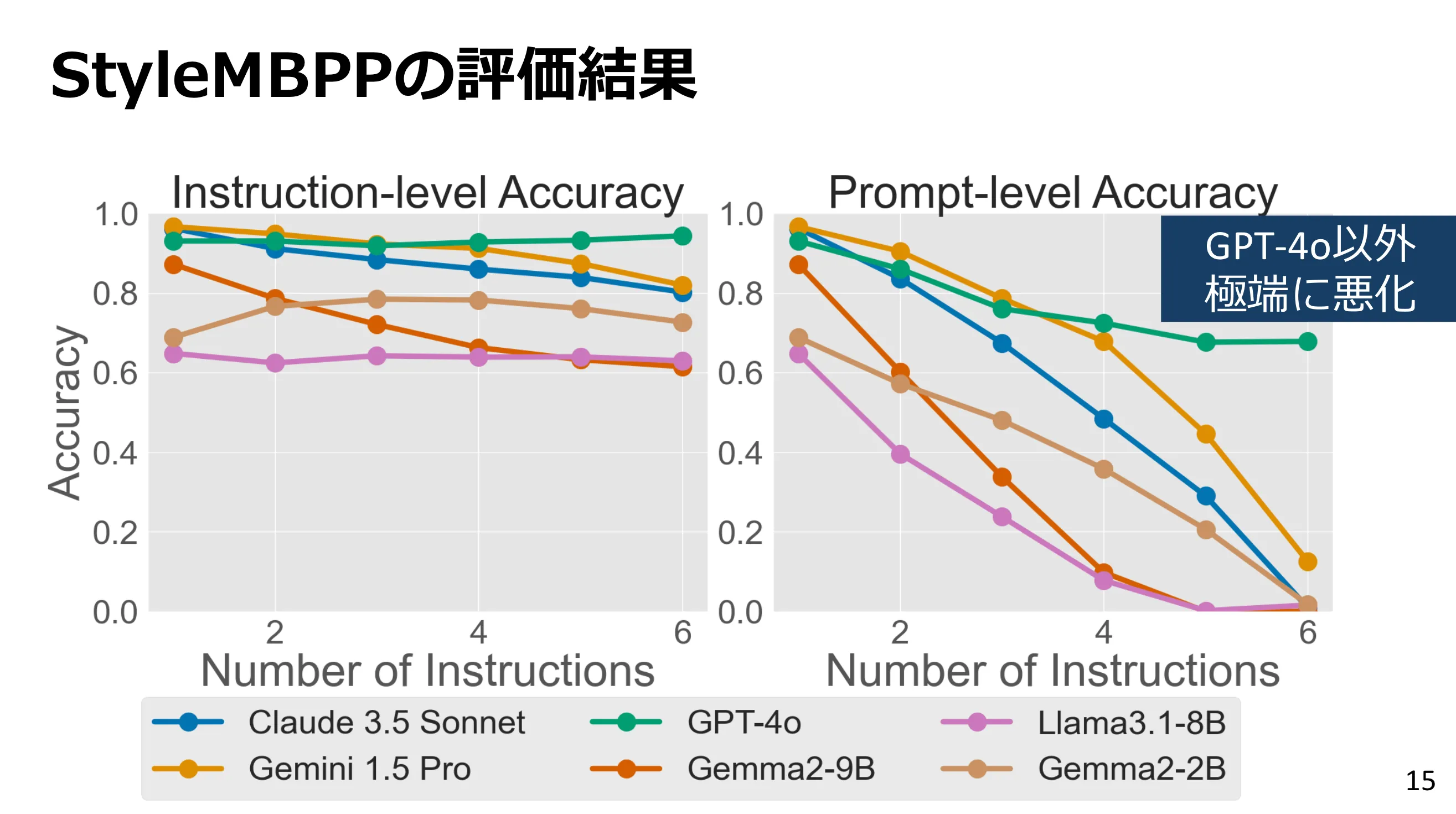
- 指示の位置や順序、内容によって守れるか否かは変わる?→あんまり変わらなそう
- 会場の感想: 感覚的には指示数は一定数まではある程度性能維持するけど、一定数を超えると一気に下がる印象
- →しかし実験結果的には、指示が一個増えるごとに線形に遵守率が低下していく雰囲気
- 会場の感想: (感想)禁止キーワードの追従が思ったより高い。。。日本語ベンチマークだと、ほぼ守られないパターンですが、英語だと守られるんですね
A2-2 オープン日本語LLMリーダーボードの構築と評価結果の分析
- 評価結果のカテゴリーごとの相関ヒートマップ はだいたい真っ赤
- →つまりどのカテゴリもガッツリ相関しておりあまりカテゴリごとの違いが見いだせなかった
- 主成分分析すると、やっぱりLLMの知能とか言語処理能力みたいなところが一番大きな影響を持っている
P2-6 LLMにおける内部表現を用いた日本語スタイル制御メカニズムの分析
- 話し方のスタイル変換(江戸っ子、お嬢様等)はもしかすると指示文自体をそのスタイルにすることで精度が改善するかもしれない
- お嬢様言葉への変換が一番難しいっぽい。原因はおそらく、常態とそんなに変わらないから。普通の話し方と違うほうがどのモデルでもうまくいきがち。
P2-13 「数」に着目したLLMの多言語能力の検証
- 何文字で答えてね、って指示をする場合の結果は、指示文自体の言語に依存して長くなったり短くなったりする
- 上の発表と合わせて、キャラ付けを行うならそもそも指示文自体も目標とするキャラの口調で書いたほうが良さそう
Q2-13 架空語に対する LLM の知ったかぶりの自動評価
- 知らない語については知らないと言ってね的な指示を加えると、確かに幻覚を減らす効果はあったが実際に存在する語も知らないと答えてしまうケースが発生した
- どんな指示を与えればちょうどいいのかはFuture work
Q2-23 LLM は日本の民話を知っているか? 妖怪知識評価データセットの構築へ向けて
- 日本語資源で学習しているモデル>中国語>英語 の順で、日本の妖怪について正しく認識していた
- 中国語が日本語に次ぐ精度だったのは、文化的な関わりが多く、共通の妖怪がいるからかもしれない
- 日本語以外で同様の研究はまだないらしいが、おそらく各国・言語で同様の現象があるはず
A3-1 大規模言語モデルはデータ漏洩を隠蔽できるのか
- 不適切なテキストがLLMの学習データに含まれることを、メンバーシップ推論攻撃: MIA から隠蔽できるか? → できそう
- LLMはテキストの丸暗記だけでなく、より一般化した知識として保持できる
- ならば、MIAから隠蔽しながら知識を保持できるのでは?
- 提案手法であるマルチタスク学習をすることで
- MIAによる検出率が大幅に低下
- QA精度はそんなに変わらず
- →表層的なデータを隠蔽したうえで、知識としては保持させることができた(?)
P3-12 LLM を用いた複数レシピに対する調理計画手法の検討
- レシピ→手順の解析→スケジュール って感じで調理計画を作成
- そこそこ上手く行ったが、工程の欠損や、温かい料理2つを出したいのに完成タイミングがバラバラになって主観的評価が低い場合が多かった
P3-17 国語科共通テスト試行調査を用いたRAGによる答案生成の評価と再検索RAGの提案
- 国語のテストで、問題文を対象にRAGした場合、RAGの結果を使ってさらに検索する場合(再検索RAG)をすると、後者だと正解率が高くなった
- 今回は検索対象の文章自体が比較的短いのでやっていないが、おそらく再々検索をすればもっと精度は上がるはず
- イルカちゃんもそのようにしたらよいかもしれない?
P3-21 学生によるプロンプトチューニングを用いた謝罪するロボットのもたらす教育効果
P3-22 生成AIによるセリフ文章を利用したタイピングゲーム
- 文体とレベルを指定してランダムな文章を生成できるタイピングゲームを作った
P4-11 LLMはASD小児と定型発達小児が作成したストーリーを識別できるか?
- できなかった。一部の実験条件で、ランダム選択よりはちょっとマシな精度が出た程度
- そもそも一般人でも難しいタスクなので、道のりは長そう
P4-12 社会的承認によって定義された心があるAI:評価方法と有効性の基礎検討
- 質問と同じ思考回路(設計発話 vs 意図発話)で回答すれば、より心があるっぽく見えるのでは?
- 出社しなくて良いと言われたので 家で作業します→対面会議が入ったので 出社してください
- 落ち着いた環境で作業したいので 家で作業します→上司に進捗を確認してもらいたいので 出社してください
- →関係なかった。常に意図発話のほうが心があるっぽいと判断された
Q4-15 真面目 LLM と不真面目 LLM で推論能力は変わるか?
- 「あなたは真面目な学生です」vs「あなたは不真面目な学生です」
- 後者だと推論能力が落ちたといえば落ちたっぽいが、ウケ狙いみたいな回答に走ることが多かった
- しかもなぜか、宇宙の話を絡めて話題を逸らすケースが多かった
- ウケ狙いに行ったのならそれはそれで推論しているような気もする?キャラ付けによってどう変化するかもうちょっと慎重に調べたら面白いかもしれない
B4-5 言語モデルの事前学習におけるバリエーションセットの効果
- 子供向け発話である”バリエーションセット”を使って事前学習させると確かに学習結果が良くなった
- 同じ意図で異なる言い回しを複数回行う文
B4-6 作業記憶の発達的特性が言語獲得の臨界期を形成する
- 背景
- 臨界期仮説: 言語を効率的に学習できる特定の期間が存在し、それを過ぎると学習能力が低下する
- Less is more 仮説: 大人は認知能力が高いゆえに文法規則の学習に時間がかかるが、子どもはそうではない
- ならば、人間の作業記憶の発達特性を学習に組み込めば効率的に言語学習が可能では?
- →YES
- ベースモデルはGPT-2
- 他の発表でもGPT-2使ってがちだった
DAY 3
今回のメイン目標、人狼知能テーマセッションの日。
三菱電機(プラチナスポンサー)企業ブース
- 社内の1問1答方式のデータをLLMに取り込んで、質問に答えるAIを作っている
- その内容はPCに水をこぼしたとかではなく「型番XYZのチップを起動するには→端子AとBを短絡させる」みたいな製品の仕様に関するものなので、イルカちゃんとはちょっと違う
- RAGとファインチューニングの使い分けってどうしたら良いんですかね?
- データの中に答えが必ず存在しているならRAG
- LLMの推論能力を活用したいならファインチューニング
D7-1 人狼知能コンテスト2024冬季国内大会自然言語部門の概要
- 今回のメインディッシュ
- 次回は万博連携企画セッションとして人工知能学会で発表予定
- 各エージェントの詳細はSlack見ればOK
- ゲーム行動と多様性で1位を獲得!
- 課題
- 話を聞いていないと解釈されうる局面
- プロンプトインジェクションバトル(10回くらいお前は人狼だろって言うと折れるとか)
- 次回は13人村をJSAI2025向けに開催予定
- 予選が来月、本戦が5月予定
- 会場の盛り上がりもよく、次回は参加者増えそう…
D7-2 プレイヤー間の論理的情報を与えたLLMによる人狼ゲーム対話エージェントの構築
- ある程度会話が長くなってきたら要約しておくみたいな処理をしている
- 発話に際しては定石をプロンプト内で教えてあげている
- 論理的構造とは?
- 役職を確定することが可能な発話を抽出してJSONで吐き出させている
- CO内容とゲーム設定との矛盾、想定可能な配役リスト、非人狼プレイヤーリスト、役職を仮定した場合の想定可能な配役リスト を論理情報として構築して次段に渡す
- 論理情報を付与することで発話は賢くなった?
- → なった
- 他のプレイヤーの発言の流れを汲み取っているか、ほかプレイヤーの推論を汲み取っているかについてもなった
- 要約プロンプト等の詳細はスライド参照
D7-3 大規模言語モデルに基づく人狼ゲームエージェントにおける戦略の自動適応
- ゲーム状況や相手の特徴によって最適な戦略は変化するのではないか?
- 人狼ゲームの戦略はサポート戦略orアタック戦略に分けられると仮定
- 味方と思う人に同調するか、敵だと思う人を攻撃するか
- 被推定率: 人狼がどれだけ他社から人狼と推定されているか
- 自動的王においてアタック戦略を用いたとき、被推定率の上昇値が小さい
- 主観的な人間ぽさについては今回の研究のスコープ外らしいが、人間ぽさは上がったんじゃないかなと思う
D7-4 戦略的発話の多様な生成を目指した人狼エージェントの構築
- LLMを単純に適用すると…
- 多様性がない
- 嘘をついてごまかせない
- 会話が終わらない
- 定型文を用いると…
- 連続したゲームで全く同じ発話が出現する
- 直前までの会話を汲んだ発言をするのは難しい
- なので、テンプレをそのまま使うのではなく、発話指示を与える方式にすることでより良くなった
- 定性評価の結果:
- バニラLLMに比べて、個性的で戦略的な発話が実現できた
- 定型文選択方式と比較して確実さが失われた
人狼知能懇親会
- 大会参加チームやセッション登壇者、オーガナイザー、スポンサーの人たちとご飯を食べた
- その後さらに、公式懇親会非参加者だけでちゃんぽんを食べに行った(オーガナイザーの先生達についていった)
- 江山楼
- 鳥海先生のイチオシで、長崎に来たら必ずこれを食べて帰るらしい
- 汁に回線の旨味がガッツリ詰まっている感じで、大変美味しかった
- 公式懇親会は飯少なすぎ・人多すぎ・野外会場で雨が降っている・参加費が結構高いなどでちょっと微妙だったらしいので、なおさら良かった
- 江山楼

DAY 4
ついに最終日。
E8-2 大規模言語モデルは他者の心をシミュレートしているか
- 視点射影という手法を用いて他者の心をシミュレートする能力を分析
- シミュレーション説を肯定する明確な証拠は得られなかった
E8-3 大規模視覚言語モデルは錯視を理解しているか
- していなさそう
- 真性錯視VQA
- 普通の錯視画像
- 右の◯に比べて左の◯は大きく見えるが、実際は同じ大きさ…ではなく本当に大きさが違う
- 偽錯視VQA
- 錯視画像に見えて、本当は錯視ではない画像
- 右の◯に比べて左の◯は大きく見えるが、実際は同じ大きさ…ではなく本当に大きさが違う
- LLMは偽錯視に騙された。
- つまり、本当に大きさが違うのに、どうせ錯視だから同じ大きさなんでしょと回答
- これは錯視を理解していないことを意味する。人間に合わせているだけ
A8-4 日本向けにファインチューニングされた中国系大規模言語モデルに北京の検閲は残るか?
- ほぼ残ってない
- 残ってたとしても中国語じゃなくて日本語で聞くならなおさら関係は軽微なはず
- 香港台湾問題、民主化運動まわりの質問は特に回答回避率が高い
P8-6 IterKey: LLMを用いた反復的キーワード生成による検索拡張生成の最適化
- Perplexity的なことをする
- RAGしてLLMが出した答えが不正確だったら、別の検索単語を使って再検索をする…を何度か繰り返す
- と大幅に回答のクオリティが上がった
Q8-2 マイクロドメインに向けたLLM における知識活用方法の検討
- 追加学習とRAGを使ったら、難しい資格試験で合格点を取れるくらいになった
企業ブース LINEヤフー
企業ブース オルツ
- 全社員一人ひとりにAIクローンを作っている
- 学習データは議事録等
- 採用でも同じようなことをして事業展開しようとしている?
- 人事と学生のクローンを作って、クローン同士で面接させて足切りするみたいな
- Q: ランダム性かなりありそうだけど大丈夫なの?
- A: それはあるが、一次スクリーニングとしては十分機能するはず
企業ブース Spiral AI
- ククリさまがすごくかわいい
- 近い内にアプリをリリースするらしい
- イルカちゃんでやりたいって言ってることをだいたい全部やってるAI
- 社内にだいぶ熱意のこもった人がおり、その人がキャラ設定からシステムまでほぼ一人で作ったらしい
- 実際、設定とかを見るとだいぶ尖っているというか、一人の狂人の情熱の賜物だと言われると納得する感がある
- 最初は社内botとして生まれたが一般公開まで至った(?)
- 今回の人狼知能大会自然言語部門のスポンサーはこの会社
企業ブース フューチャー
- コンサル会社としていろいろやっている
- 特に 貿易投資相談のお問い合わせ自動化 に関してはやっていることがほぼイルカちゃん
- LLM + RAG でお問い合わせ回答のドラフトを作る
- 技術的な話を色々聞かせてもらった
- Q. RAGとファインチューニングってどう違うの?どう使い分けたら良いの?
- RAGの方がお手軽だから、まずはRAGからやるべき
- ファインチューニングについては、以下の条件を満たすなら良いかもしれない
- LLM+RAGの精度によっぽどの不満がある
- タスクが単純明快
- 出力フォーマットを厳密に守らないとならない
- プログラムの過程として使うので厳密にJSON形式で出さないといけないとか
- データが十分にある
- 問い合わせ対応の自動化についてダイレクトに聞いたら、問い合わせ内容すべてを訓練データが網羅する必要があるがそれは非現実的だろうからやめたほうが良いんじゃないかな、という話だった
- お金と時間がある
- 一度訓練するのにもコストがかかるし、内容を更新していかないといけないならなおさら
- 例: 新聞記事から見出しを生成するタスクは、これらの条件を満たしているのでファインチューニングでやっている。逆に、貿易投資相談のお問い合わせ自動化はどれも満たせていないのでRAGでやっている
- Q. LLM+RAGのハルシネーション対策ってどうしたら良い?
- 検索結果にないことは答えられないので、まずはデータを増やして検索精度を上げる
- それでもハルシネーションはゼロにはならないので、ゼロではない前提のフローを組むべき
- 作ったあとにLLM as judgeで回答の精度を判断させ、悪ければ棄却なり再検索なりする
- 参考情報として検索結果を提示する
- ファインチューニングを行う場合、これに関してもRAGよりだいぶ困難になるのでやはりおすすめしない
- あくまでドラフト生成のためだけに使い、最終的には人間をフローに介在させる
- Q. RAGとファインチューニングってどう違うの?どう使い分けたら良いの?
Q9-20 大規模言語モデルを用いたStory Intention Graph の自動生成の精度改善
- SIGとは、物語をグラフ構造で表現したもの
- LLMを使って、物語からこれを自動生成することに挑んだ
- shotをプロンプトに追加する(例を与える)と精度が改善した
D10-5 質問誘導に基づくアンケート対話システムの開発
- 雑談の中でアンケートを実施する(質問誘導)ことで、回答者への負担を減らしたい
- LLMを使って、質問に対する応答をいくつかの種類に対応付ける
- 自由記述回答になるので、それを選択肢に当てはめる必要がある
- このシステム経由で取得された結果と、普通に選択式で選んでもらった結果の完全一致率はもう一歩という感じだったが、部分一致率はかなり高かった
- テキスト対話に比べて音声対話では一致率が下がったが、これは音声対話のほうがテキスト会話より考えられる時間が短いからかもしれない
- 遷移カテゴリー装置(?)
- 誰と話しているとどういう話題が出やすい、みたいなことを詳細に調べた研究がすでにあるらしい
D10-6 Multi-Relational Multi-Party Chat Corpus: 話者間の関係性に着目したマルチパーティ雑談対話コーパス
- 既存のチャットシステムはだいたい1on1なので、複数人対話に対応したコーパスを構築した
- 工夫として、3人全員が初対面のグループだけでなく、2人が家族で一人が初対面みたいなグループのログも取った
- 会話結果に対する主観評価では、後者のケースで初対面の人の評価が低くなりがちだった
- 自分だけ蚊帳の外になりがちなので、それはそう
P10-9 なりきり雑談システムを評価するためのキャライメージの評価者間一致に関する検証-4択クイズを用いた原作者とファンの比較-
- 言ってるけど原作では言ってないだけ 問題を扱った調査
- 10年前のあるビジュアルゲームのキャラクターについて、
- 本当の発言
- ファンのイメージで作った発言
- 口調が不適切な発言
- 内容が不適切な発言
- の4択を作って、原作者とファンと知らない人でどれくらいの正解率かを調べた
- どの作品を使ったのかすごく気になるが、それは公開しない約束らしい
- 原作者は98%正解
- そもそもこの数字驚異的じゃないですか?
- ファンは不適切な発言をめったに選ばなかったが、本当の発言を選んだのは6割程度
- 知らない人はランダムよりはわずかに無関係な発言を選ぶ率が低い
- 会話の抜粋を問題文として与えているので、その短いやり取りからでもキャラが読めたためと思われる
- 知らない人から見たとき、真の発言とファンイメージ発言は見分けが不可能
- 作品を知ってから時間が経てば経つほど、原作発言よりファンのイメージ発言を選びやすい傾向がありそうだった
- つまり、キャラのイメージがファンの中で熟成されて本来の姿から乖離していくということかも
0313-1450-招待講演2_脳からの意味情報解読で探る視覚と言語の境界線-a会場
- 物体、単語レベルの特徴では、アクションや社会的なインタラクションの認識に重要な相互作用、関係性を捉えられない
- ギター、人間、人間とギター、ギターを弾く人間 …の画像を提示したとき、それぞれで異なる脳領域が活性化する
- マインドキャプショニング
- fMRI信号から、脳に表現されている視覚的意味情報をテキストへ変換する生成デコーディング手法
- 何度もイテレーションを繰り返していると、だんだん動画→[被験者の脳]→文章への変換が深化して正確な動画の表現になっていく
- 脳活動をよく説明できる言語モデルの特徴量ほど、高い文生成の性能をもつ
- 言語野を損傷している人でも視覚的意味は把握できる
- 言語野はこの機能に寄与してはいるが、必須ではなさそうらしい
- 画像を見ている間の脳信号を文章に変換するモデルを流用して、想像している内容についてもかなり高い精度で記述させることに成功した
- 単一施行の脳活動から、想像している内容の文章記述を生成できる?
- ある程度の精度で生成できているっぽい
- 一回限りしか体験できないような場合でも行けるかも
- e.g. 夢の記述(!!!)
- ロマンがありすぎる話だ
- ゆくゆくは、言語に頼らない思考ベースの脳ーテキストコミュニケーションが実現できるかも
クロージング
- スポンサー賞の副賞としてMeta Quest、HHKBのキーボードx2、万博入場券x10などなどが渡されていた
- 次回の開催は
- 2026-03-09 - 13
- ライトキューブ宇都宮
- 三菱電機の方が来年ダイアモンドスポンサーになるって宣言してた
ここまででNLP2025の話は終わり
DAY 5
朝の飛行機で福岡から東京へ戻りました。以下感想です。
NLP2025について
すごく良い大会だった。
- 自分が経験した中では最大規模だった
- 運営がとても円滑だし、良い大会にするための工夫が至るところに散りばめられているなと思った
- 特に驚いたのが大会公式Slackの運用
- 発表を見ながらSlack上で質問したり感想を呟いたりできる
- 詳しい人の意見とか補足説明とかが聞けて大変良い
- 質問時間に質問できなくとも、Slackに書いておけば発表者が後からコメントを返してくれる
- ポスターセッションを聞きに行くにはスポンサーブース前を通る必要があるように設計されている
- 毎日異なる長崎お菓子が用意されるのも素晴らしい
- 特に驚いたのが大会公式Slackの運用
- 発表内容が幅広い
- 悪く言えば玉石混淆だが、良く言えばハードルが低い
- 特に応用系の発表だと、「◯◯を解決するためにGPT-4を使ってみました」くらいの発表も多かった
- 詰めてくる怖い人も(たぶん)おらず、全体的にすごくまったりとしていた
- 研究に力を入れている企業ならばここでブース出展するのは間違いなく良いだろうなと思った
- 同業の人や学生に、自分のところの研究をアピールできるいい機会のはず
- 新卒採用の一環的な要素はかなり強そう。学生限定の非公式懇親会がいくつも開催されていたし、Spiral AI社は人事の人がブースを回していた
- 研究成果が特にないのに出展してもあまり意味は無いかもしれない…
長崎について
長崎は本当にいい街!
- 景色が良い
- 坂道が多いのは地元の人としては大変だろうけど、観光するには大変素敵
- 歴史的な面白みがある(主観です)
- The 長崎的なものはどれも、作られた流行ではなく歴史的経緯に基づいている感がある
- それでいて変に歴史の深さをアピールしたり、都会派を気取ることもない(超主観です)
- 見るべきものも食べるべきものも大量にありつつ、地方都市の良さみたいなものをちゃんと堅持しているのが良いなと思った
イルカちゃんに役立ちそうな知見
とりあえず、現時点でイルカちゃんに役立ちそうだなと思った知見です。 (ちゃんとした報告書的なものはまた今度作ります)
Lost in the middle問題
- コンテクスト長が長くなると中間で与えた情報を無視しがち
- これに対応するためのアドホックな対策として、重要な指示は文中で何度か繰り返して与えると良いことが知られている
- Attention が文頭、文末、区切り記号に偏りがちらしい
P2-6 LLMにおける内部表現を用いた日本語スタイル制御メカニズムの分析
- 話し方のスタイル変換(江戸っ子、お嬢様等)は、スタイル変換の指示文自体をそのスタイルにすることで精度が改善する。
- お嬢様言葉への変換が一番難しいらしい。原因はおそらく、常態とそんなに変わらないから。
P2-13 「数」に着目したLLMの多言語能力の検証
- ◯文字で答えてください 系の指示は、日本語で指示して日本語で答えさせたり英語で指示して英語で答えさせる場合はだいたい守ってくれる。
- 英語で指示して日本語で答えさせると、指示よりも短くなりがち。逆だと長くなりがち。
- イルカちゃんの応答が無駄に長い場合に役立つかもしれない。
P4-12 社会的承認によって定義された心があるAI:評価方法と有効性の基礎検討
- 設計発話(理系っぽい偏屈そうな喋り方??)と意図発話(お気持ち重視な喋り方??)がある
- 話し手のスタイルに合わせて回答すればより心があるっぽく見える…というわけではなく、常に意図発話をしたほうが心があるっぽく見える
- 設計発話による会話の例
- 出社しなくて良いと言われたので 家で作業します→対面会議が入ったので 出社してください
- 意図発話による会話の例
- 落ち着いた環境で作業したいので 家で作業します→上司に進捗を確認してもらいたいので 出社してください
- 設計発話による会話の例
D7-1 人狼知能コンテスト2024冬季国内大会自然言語部門の概要
- ムダに長い発話は人間っぽさを損ねる
- 自分が出したエージェントは、勝率では下から2番目だったが主観評価5項目中2項目でトップだった
- ので、スポンサー賞がもらえた!
- イルカちゃんで培った知見が生きた
Spiral AI の ククリさま
- イルカちゃんでやりたいって言ってることをだいたい全部やってるAI
- 社内にだいぶ熱意のこもった人がおり、その人がキャラ設定からモデルまでほぼ一人で作ったらしい
- 最初は社内botとして生まれたが一般公開まで至った
- なんと人狼知能大会のスポンサーはこの会社だった!ので、追加で話を聞くことができた
旅情編
NLP2025や業務とはあまり関係のない話はこちらに切り分けました。
DAY 0
2025-03-09日曜日。大会の前日。
遠足前日の気分が発生してしまい、3時間くらいしか寝れませんでした。
飛行機
東京から長崎へ直接飛ぶ飛行機はかなり高かったので、まずは福岡空港へ向かって福岡で1泊し、翌日に長崎へバスで向かう作戦を取ることにしました。帰りも同様。
12:10 成田発の飛行機に搭乗。座席はD、つまり通路側だったのだが、なんとドアクローズ後も窓側2席が空いている!窓側に移動させてもらいました。
成田から新千歳に向かうことはしばしばあるものの、西に向かうのはだいぶ久々なのでめちゃくちゃ嬉しかったです。
機内アナウンス。左側に富士山、右側に諏訪湖が見えるらしい。自分は右側なので、富士山を拝むことはできませんでした。
福岡空港のクレカラウンジでは、ドリンクバーかビール(スーパードライ / 一番搾り)が選べた。一番搾りを選択し、昼からキメてしまいました。
ひらおの天ぷらを食べる
情シス内で教えてもらった天ぷらのお店。本店が福岡空港から徒歩20分程度のところにあるので、福岡初飯はこちらでいただくことに。
店の外まで列が続いており、最終的にありつくまでに50分くらいかかった。しかしそれに見合うだけの美味しさだった! 衣のサクサク感が素晴らしく、つゆにつけてふにゃふにゃにしちゃうのがもったいなく感じるくらい。
イカの塩辛が美味しいということで、+50円で大盛り(通常一皿のところを二皿もらえる)を追加。実は自分はイカの塩辛にちょっと苦手意識があったのだが、これもまた美味しかった。柚子酢のおかげでさっぱり系の味でした。
チェックイン
宿泊場所については、もともとは現地をふらつきつつ、最悪ネカフェ泊をする予定だった。 しかしひらおでお腹いっぱいになり速やかに横になりたくなったので、友人から提案されたホテルキャビナス福岡に泊まることに。1泊4000円!
初のカプセルホテルだったのでちゃんと寝られるか心配だったのだが、お風呂とサウナに入ってちょっと仮眠を取ろうとしたらそのまま爆睡してしまいました。
禁煙室は満室でやむなく喫煙室にした。喫煙室といっても、喫煙所と同じフロアのカプセルというだけなのだが、他のフロアには無い独特の匂いがあってなかなか厳しかった…
DAY 1
福岡から2時間半くらいバスに乗って長崎へ。無事に大会開始ジャストに会場へ着きました。

- スーパーノンストップ九州号
- だいたい150分、2900円で行けます
- wifiもUSB充電ポートもあって素晴らしい
- (ここに接続難易度の高いWifiの画像を挿入)
来たぜ長崎! (画像を挿入) 会場の出島メッセ長崎。綺麗だしアクセスも良い。 (画像を挿入)
宿泊
長崎滞在中は3泊連続でみなとサウナという施設に泊まりました。


- 宿泊税込みで5000円のカプセルホテル
- 大浴場がとても良かった
- かなり熱めのサウナ(オートロウリュつき。頻度は5分か10分?)
- -10度くらいの冷凍庫みたいな部屋
- 屋内だけど窓が開いてるので実質外気浴が可能なととのい部屋
- そもそも宿泊人数がそれほど多くないので、混雑とは無縁で休息できたのが助かった
DAY 2
昼食
ところで、会場内には休憩スペースが用意されています。
- 常時コーヒーとオレンジジュースが飲み放題
- 毎日異なる長崎お菓子が用意される
- お昼休みにはコンビニの惣菜パンが追加で用意される
と至れり尽くせり。2日目の昼食は長崎お菓子とコンビニパンで済ませました。
ここで食べた琵琶かすたってお菓子がめちゃくちゃ美味しかったので、お土産に買って帰ることに。
夕食
大会公式Slackで紹介されていた中華 大八 というお店で皿うどんを食べました。
http://
かなりの人気店のようで、昼食で行こうとしたら既に30人くらい店外に並んでいた。 そのため、夕方の営業開始30分前から並ぶことにしました。
ツウは太麺で行くらしいが、自分は初めての皿うどんだったので無難に細麺に。 めちゃくちゃ美味しいしコスパも抜群で、皿うどんという料理自体が好きになりました。
浜町探索
全国各地を行脚している友人曰く、知らない街に来たときは、早い段階でいい感じの酒場に入って情報収集すると良いらしい。自分もそれをやろうと、ランダムなスナック(?)に初挑戦してみることにしました。
繁華街浜町にある、蝶々夫人という店に行こうと22時頃に決心。理由としては、この記事を見つけたから。

- 長崎新聞の取材を受けているということは、少なくともヤバい店ではないはず
- なんなら新聞社の人の行きつけだったりするのかもしれない
- 今年で39年目の超老舗という安心感
- 飲んだ帰りにトマトラーメンを食べに行ける立地
実際大正解で、有益な長崎情報をたくさん集めることができた。
- サウナが好きなら稲佐山の麓にある以下の施設がおすすめ
- 稲佐山温泉ふくの湯
- 稲佐山温泉ホテルアマンディ
- 特にこちらは景色が良い
- 宿泊場所のみなとサウナは意外と歴史のある施設
- リフォームされたのか外も中も綺麗だったから、全く気づかなかった(言われてみれば確かに、って感じ)
- 長崎市にサウナの概念を持ち込んだ初の店だし、街なかでサウナに入るなら現在でもほぼ唯一の施設
- 昔は施設内に居酒屋があり、そこの海鮮が地元の漁師も認めるくらい美味しかった
- 中華 第八について
- 店主と知り合いらしい
- ポジショントークを抜きにしても、市内で皿うどんを食べるならここが一番美味しいしコスパが良い、いい選択をしたとのお墨付きをもらえた
- 意外と他のメニュー(特に中華丼)も美味しい
- 長崎みやげについて
- 福砂屋のビスコチョが美味しいし日持ちするから無難におすすめ
- 長崎駅の福砂屋で一人二個まで買えるが、それを知らない人が結構多い
- 自分もビスコチョには目星をつけていたが、長崎駅でも入手できるとは知らなかった
- その他諸々の人生相談
そこそこお金はかかったものの、確かにこれはハマっちゃうかも…と思いました。
夜食
飲んだ後の夜食として、予定通りらーめん柊のトマトラーメンを食べました。

めちゃくちゃ美味しかった!トマトなのであっさりはしつつも、わりとガッツリ寄りのトマトラーメンでした。お酒を飲んだ後だったので、なおさら良かったです。
(ここに画像を挿入)
- 0時にもかかわらず店の前に5人くらい並んでいた
- 並んでる間、福岡から来たという人と話して地元のラーメン情報を聞くことができた
- 長浜屋台 一心亭 本店
- 1杯600円程度でちゃんと美味しい
- 店によって結構味が違うので本店に行くべき
- 長浜屋台 一心亭 本店

DAY 3
軍艦島
5コマ目と6コマ目のメモが一つもないのは、午前中にサボって軍艦島(正式名称: 端島)に行っていたからです。
見ようと思ってたけど見れなかったやつは以下の通り。後で公開スライドを探さねば…
### B5-5 大規模言語モデルを用いた我が国の対米外交における調書作成支援システム
### B5-6 ChatGPTを活用した高知県観光支援システムの構築
### P5-2 レビュー情報を用いた LLM による観光地比較表生成
### P5-12 医療事故・ヒヤリハットに関する要因・対策案生成ベンチマークの提案
### Q5-13 大規模言語モデルを用いたソースコードからのドキュメント生成能力調査
### Q5-22 LLMを用いた発話生成のキャラクター性付与におけるプロンプトとファインチューニングの効果比較
### D6-4 AIは人間らしく話ができるか:ロボットと仲良くなるために
### P6-9 大規模言語モデルを用いた生成による企業の業種体系の拡張
### P6-21 LLMを用いたクロールデータからの人物略歴文抽出軍艦島に行くのは5年ぶり2回目です。前回は学生の頃で、これまた長崎のグラバー園で開催された学会の参加中に行きました。
長崎には、軍艦島上陸ツアーを開催している会社が5つくらいあります。これらの公式に許可されている会社のツアーでないと上陸できません。昔は漁師さんにお願いして連れて行ってもらったりとかもあったようですが(羨ましい)。
前回は「軍艦島コンシェルジュ」を利用しましたが、今回は高島海上交通の「軍艦島上陸クルーズ」を利用しました。唯一予約が空いていたのがその会社だったからです。幸い、その日は雨の予報が出ていたためか予約枠にかなり空きがありました。
高島海上交通の特徴は、わりと安いことと、道中で高島に寄ってくれること。
9:10 に港を出発。40分くらいで高島に到着。ちょっとした博物館と軍艦島の模型がある。
猫。
今回は反時計回りに島を周遊するとのことだったので、早めに乗船して左前方の位置を確保。
軍艦島が見えてきた!
2年前に大きな建物が大きく崩壊したらしい。画像を比較してみるとたしかに…。
ガイドさんの話を聞きながら観光用通路の奥まで向かった後、15分の自由行動……なのだが、ガイドさんがしてくれる補足説明が面白くてずっと聞いてしまった。
第二竪坑入坑桟橋跡。ここでボディチェックを受けてから、桟橋を通って入坑口に進むらしい。
さらば軍艦島!
→ 人狼知能テーマセッションに続く
DAY 4
おみやげ購入
福砂屋のビスコチョを長崎駅へ買いに行きました。駅の手前の商業施設内の福砂屋ではなく、長崎駅の建物内にある「かもめ市場」の中の福砂屋が正しい(一敗)。その店舗の裏にひっそりと自販機が置かれている。
一敗したときに上記の説明をしてくれた上、もう片方の店舗に電話をかけて自販機内の残りビスコチョ数を調べてくれました。やさしい。
日本二十六聖人記念館
昼休みの時間を使い、大会Slackで紹介されていた日本二十六聖人記念館に行きました。建物が立派。 長崎(主に)とキリスト教の歴史が一通りわかるし、展示物も面白いものがたくさんあって良かった。
類似でもっと有名な施設として大浦天主堂がある。しかし、どちらも行った人によれば日本二十六聖人記念館の方が展示内容、静謐さ等の点でオススメとのことだった。
カフェ&レストラン ボエーム

トルコライスを食べるため、駅チカで評価の高いこの店に行きました。
トルコライスは美味しいし、セットのサラダにはゆで卵がついてくるし、食後のコーヒーが出てくるタイミングは完璧だし、デザートにケーキも付いてくるしで最高でした。観光客のための店ではない、落ち着いた雰囲気の喫茶店って感じなのもまた嬉しい。
漫画の本棚があるのは地元民に長年愛されてきた証(たぶん)。
さらば長崎!
バスに乗って長崎から福岡へ。
締めに福岡の飯を食べなければなりません。
とりかわ 博多かわっこ
九州ならではらしい、ぐるぐる巻きにした鶏皮串を食べに行きました。串のサイズが思ったより小さくて驚いたが、外はパリッと、中はジューシーって感じでとても美味しかった。 もっといろんな串を食べてみたかったものの、後述する屋台の予約が迫ってきたので鶏皮だけしか頼めませんでした。
(ここに画像を挿入) うまい話には裏がある…
屋台けいじ
鶏皮と合わせてどうしても行きたかった屋台。他のお客さんと方を寄せ合いつつ飲むタイプのお店。 5年くらい前にも行ったのですが、地元の常連さんが集う店という感じで、すごく雰囲気が良かったのです。
Youtubeに上げている動画が人気らしく、それを見て来たという人が多いらしい。 最初は「地元民の店じゃなくなっちゃったのか」とがっかりしていましたが、これはこれですごく楽しかったです。i18n。 国内から出張で来た人だけでなく台湾や香港から来た人もいて、台湾語や広東語を学びながら出川イングリッシュでコミュニケーションをしました。
香港から来た方がお酒に強く、どんぶりレモンサワーとかいうヤバいものを2杯飲まされてベロベロになってしまいました。 とりあえず覚えていることは以下のとおりです。
- 台湾に行くなら春か冬が良い
- 夏は暑いし、冬は冷たい雨がよく降るため
- 屋台で魯肉飯、牛肉麺、ライチを食え
- 「ありがとう」は謝謝ではなく多謝(どーしぇ)
- 台湾語と広東語でちょっと発音が違う?
- 多言語が話せるのは良いなと思った
- 大学院まで英語の研究をしていた出版社の人、商社勤務の人、常連さんはかなり流暢な英語と多少の台湾語/広東語で非出川なコミュニケーションが取れててすごかった
DAY 5
飲み過ぎによりトイレでリバースする、寝湯で1時間くらい気絶するなどのイベントが発生したものの、5時くらいに就寝して8時に起床できました。
ホテルから空港は地下鉄で15分。福岡は市街地から空港がすぐそこなのが本当に便利です。
つつがなく飛行機に搭乗し、成田空港に到着。そこからは京成成田スカイアクセス線で都内まで向かい、お土産を会社に持っていきました。
これにて旅の話も終わりです。ご清聴いただきありがとうございました。
以下、長すぎる講義メモの置き場
0310-1300-t1-言語モデルの内部機序_解析と解釈-a会場
- LLMは一般的にブラックボックスみたいな言い方をされるが、実はわりとホワイトボックス
- BERTの浅い層では品詞タグ付けを、深い層では共参照解析をしているっぽい くらいはすでにわかってる
- 一方、パラメータを全部見るというのはつらい。そこで、抽象化や単純化が必要になる
- デビッド・マーの3つのレベル
- 計算のレベル
- アルゴリズムと表現のレベル ←ここで解釈しなければならない
- ハードウェア・実装のレベル
- そのうえで、我々が知りたいのは抽象化された表現だけでなく、それが世界とどう関わるのかを知りたい(A + B = C ではなく、 king + women = queen という関係を知りたい)
- 会場内の全員がtransformerを知っていて面白かった(説明が飛ばされた)
「モデルを使ううえでの “理解” ってなに?!」に一本だけ論文をおすすめするとこれがわかりやすいかもしれません!
- Positive / Negative 文章に対するニューロンの発火を調べると、感情に対応するニューロンが特定できる
- 特徴量を抽出するには?
- プローブって物を使う
- プローブを地理情報に対して学習させると線形になる。つまり、地理座標はおそらく線形にエンコードされている
- 辞書学習
- 概念の数 > モデル次元 の場合には、一つの次元に複数の概念が含まれると想定される
- この場合、よりスパースなオートエンコーダーで隠れ状態を復元することで、重ね合わせをほどくことができる
- 例:ゴールデンゲートブリッジの話題や画像にだけ発火するものとか
- プローブって物を使う
初代通天閣の特徴量には凱旋門の特徴量とエッフェル塔の特徴量が入ってたりするんだろうか word2vec全盛の2015年ぐらいに東京タワー-東京+横浜でマリンタワーがだせたりするのは確認しましたね。
直接の回答になっていませんが、各社の :sae: デモ、ぜひ触ってみてください!
GPT-4:https://openaipublic.blob.core.windows.net/sparse-autoencoder/sae-viewer/index.html
Claude:https://transformer-circuits.pub/2024/scaling-monosemanticity/features/index.html
すごい。
- こうやって表現空間を解釈することで、モデルの内部機序を理解できる
- mod 60の足し算を言語モデルで学習させたとき、良いモデルの通知の内部表現は(PCAで2次元にすると)きれいな円形になる
- GPT-2とかの事前学習済み言語モデルでも、曜日とか月とかは周期上に表現されている
- 「概念グリッド」を与えまくると、そのグリッド構造がモデルの内部表現に反映される
- ↑質問
- 次元の呪いとか、高次元に飛ばせば見たいものが見れる的なやつとか、メロンパン的なやつだったりしない?
- 可能性はあるが、プローブを改善していけば解決するはず
- そもそも 内部表現 の 表現 って?
- うまくプローブできる
- それを抑制するとモデルの性能が落ちる
- 反事実的な編集によって介入すると、あたかも入力が変わったかのように出力が変化する
- 代表的な因果的介入手法: Activation Patching
- 移植して結果が変わるかどうかを見ることで、内部の計算過程が考察できる
- 昔の脳科学みたいなやり方だ
- ゴールデンゲートブリッジ特徴を増幅させると、我こそはゴールデンゲートブリッジみたいに言い出す
- 誕生年軸をずらすと実際に出力が変わる

- 文脈情報はどう参照している?
- 特定の品詞、単語の遺贈関係に強く反応するヘッドがある
- Retrieval heads
- 長い文脈から、必要な情報をピンポイントに参照するヘッドが存在する
- そしてこれを削除すると性能が劣化するので、確かに機能していそう
- 長い文脈から、必要な情報をピンポイントに参照するヘッドが存在する
- Attentionの奇妙な傾向
- 文頭、文末、区切り記号に注意重みが偏る
- ROOT ばかり見ても有益な情報はないのでは?
- そんなわけで、注意重みを解釈として本様に良いのか、RNN+Attentionの時代から議論がある
- 拡張した手法を用いると、奇妙な傾向が弱まる
- パラメータやモジュール出力を語彙と紐づけることで、内部の機序がわかる
- 重み行列をそのまま見ても何もわからないが、それを埋め込み行列に射影して観察すると、こういう入力が来たらこういうパラメータが反応しやすい みたいなことがわかる
- 計算過程の分析手法が4パターン紹介された
- 後でスライドちゃんとよもう
- Induction heads が学習されるタイミングと、精度がぐっと上がるタイミングが同じであることが経験的に知られている。たぶんこれはすごく重要。
質問コーナー
- Attentionの言語依存性?
- まだわかっていない謎のひとつ。今後の課題
人間の認知能力をAIが超えはじめている今、部分的・近似的になら AI を解釈することはできると思いますが、その知見はわかった気になれる以上に何かの役に立つのでしょうか(解釈性研究の行き着く先が知りたい)
- ゲキムズなのでスレッド内でレスバをすることになった
質問終わり
- そもそもなぜ内部表現は世界の情報を持てるのか?
- プローブを使うと緯度経度が線形に保存されているっぽいことがわかるが、もちろん言語モデルは世界を歩き回っていない
- 仮説1: プラトニック表現仮説
- 言語・画像等各モダリティのデータには、この世界の共起構造が写し取られている
- ゆえに、各モデルが学習する表現は世界の構造と同型となる
- 仮説2: 集合的予測符号化仮説
- LLMは世界と接地していないが、世界に対するセンサーとしてのヒトの集団が作り上げた言語は、世界の構造を反映している
哲学者側からの応戦だと、LLMは世界モデルをもつがこれ。
From task structures to world models: what do LLMs know?
返答はこちら。身体性がキーワードです。
LLMs don’t know anything: reply to Yildirim and Paul
- in silico <=> in vivo
- 内部機序がわかれば本当に勝ち?
- アカデミックの人間として疑問を投げかけねばならない らしい
- 大きな仮定として、内部機序と具体的な概念・機能を一対一対応するものだと考えている
- 局在化を仮定
- ヒトの持つ概念と言語モデルが持つ概念の対応が本当に取れるのか?
- 言語モデル as 表彰計算機
- 仕組みは簡単だが作られた結果は難しい。これはライフゲームと同様
- 言語モデルだけ見ていても表現・アルゴリズムレベルの理解は得られない?
- 理解のための方法とシステムのアンマッチ
- これを取り除くと○○が出来ないからこれが○○にかかわっている≠○○だけにかかわるニューロンはこれだ!
- 本当にこの方向でいいのか?はよく考える必要があるが、内部機序に迫ることで何かがわかってきているような気がする
0310-1445-t4-人工知能の哲学入門-b会場

- SF映画より実は推理小説が好き
- 第二次AIブームまではAI研究者と哲学者で活発な論争が行われていたが、90年代以降議論は下火になった。飛躍的な進展を遂げた今、再検討が必要なのでは?
- 古典的人工知能
- 知能の本質は計算であり、アルゴリズムとして表現可能
- コンピュータはアルゴリズムを実行可能
- ゆえにコンピュータは知能を持ちうる
- 問題
- 現実世界の課題は複雑。手書き数字の認識くらいならともかく、犬を識別したりチェスをさせたりはできない?
- 現実世界の課題はopen-ended
- 常識を明示化する必要がある?
- 必要な知識を特定できたとしても、状況に応じて必要無知識を素早く特定するのが困難
- 組み合わせ爆発・フレーム問題
- 多くの規則には例外がある
- 例外を除けば赤信号では停車すべき
- 要するに、単純な世界ではうまく行っても複雑な世界には適用できない
- 第二次AIブームまでの哲学は、古典的AIの問題を正しく指摘していたが、なぜ人間は同様の問題に直面しないのかを説明できていなかった
- 現在の人工知能
- データからの学習とNNの利用
- 特徴量設計が不要
- 大規模なDNNは不k図圧な関数を表現している
- 入出力を工夫すれば様々な課題に利用可能
- 入出力のうまいベクトル表現を考えればOKなので
- データからの学習とNNの利用
- 人工知能の哲学に関する主な問い
- 人工知能そのものに関して
- AIの限界は?DNNは何をしているのか?
- 認知科学との関連で
- DLは人間の認知の原理か?
- 人工知能そのものに関して
- AIの限界は?
- 古典的な批判では、AIには原理的にできないタスクがあるんだという話が強かった
- が、これは非生産的だし技術の進歩で反証されちゃう
- 生産的な問は、特定の手法で実現困難なことは何かということ
- 課題1: 大量の訓練データが存在しない課題への対応
- 画像認識はできても政策決定はできない
- 課題2: 汎用人工知能の実現
- 汎用かつ高性能な人工知能は実現可能か?
- チャーチランドの状態空間意味論
- 特徴量内の構造は現実世界におけるなんらかの状態を反映している
- 現在の人工知能の倫理的・社会的問題
- バイアス、透明性、AIアラインメントなど
- いずれも現在の人工知能の仕組みに由来する問題
- AI開発者の倫理観を高めれば解決する問題ではない
- バイアス、透明性、AIアラインメントなど
- DLは人間の認知の原理か?
- コネクショニズム vs 計算主義
- 現在の人工知能はコネクショニズムの正しさを示しているように見える(そう単純な話でもないが)
- 自己符号化の原理は脳の基本原理でもあるかもしれない
- 事象同士の確率的関係は脳における知識の基本形式かもしれない
- 言語を巡る問い
- 文法ミスなし、ハルシネーションの克服、訓練データが少ない内容に関する文章生成
- →これらは⼈間にとっても実⾏が困難な課題なのでは?
- 状態空間は一体何を表現しているのか?
- LLMは語と語の確率的関係以上の情報を表現しているのか?
- 文法ミスなし、ハルシネーションの克服、訓練データが少ない内容に関する文章生成
- LLMの言語仕様に関する3つの見方
- 意味理解を書いているので十全な言語仕様は不可能
- LLMは人間と同じ言語仕様のメカニズム
- メカニズムは異なるが意味理解なし十全な言語使用が可能
- LLMは人間の言語実践に寄生的?
- LLMは語と現実世界のつながりを欠く?
- 中国語の部屋に近い
- LLMと人間の言語使用が本質的に類似しているとしたら、それは何を意味するのか?
- 言語の使用説(ウィトゲンシュタインとか)では、言語外使用こそが言語使用の本質って考えている
- が、現在のLLMに可能なのは言語内使用だけ。従来の発想と逆じゃないか
- 外在主義 vs 内在主義
- LLMは従来とは異なるタイプの内在主義の可能性を示唆している?
古い記事

アコースティックギターに挑戦した軌跡です。練習方法、コツ、おすすめの原神の曲の譜面等もご紹介。

関連するかもしれない記事

日帰り弾丸旅行に行ってきました。その旅行記と写真集と感想です。


アコースティックギターに挑戦した軌跡です。練習方法、コツ、おすすめの原神の曲の譜面等もご紹介。

久しぶりにPC版『グランド・セフト・オート・サンアンドレアス』をプレイしています。MOD導入による快適化や、色褪せないゲームの魅力、ストーリーについて語ります。



Youtuber Mujin氏が詳細に解説した、2024年からのSAG-AFTRAビデオゲームストライキと、人気ゲーム『原神』を巡る複雑な騒動についての動画紹介と、その内容のまとめです。




原神の人気キャラクター、胡桃(フータオ)の伝説任務をプレイしました。その感想と、魅力的なストーリーとキャラクター性、そして「英雄の旅」との関連についての軽い考察です



