






目次
Google Cloud Platform Professional Machine Learning Engineer(以下、MLE)の取得に向けて勉強しているので、そのメモ。

これは学習メモなので、間違った情報が記載されている可能性もあります。
サービス一覧
難易度別サービスの選び方
問題文ではよく、チームに特定の知識があるか、ビジネス上のニーズがどこにあるかが記載されている。
- なるべく労力をかけずに
- チームにコードが書ける人も SQL クエリが書ける人もいない
- 機械学習の経験を持つ人がいない
- ノーコードソリューション
などなど。
文言と適切なサービスのざっくりした対応は以下の通り。
SQL を書ける人がいる/データが BQ 上にある
BigQuery ML を使う。
BQ 上で SQL を書くだけでモデル構築が可能なため。
ただし、以下の制限があることに注意する。
- 利用できるモデルは限られており、テーブルデータしか扱えない
- BQML はモデルの自動デプロイ等には対応していない
画像や音声を扱う場合や、モデルの継続的インテグレーションまで行いたい場合は、BQML ではなく AutoML を利用する。
機械学習に詳しい人がいない
Pre-build APIs(構築済み API)を使う。
モデルの学習が不要で、API にデータを投げるだけで色々なデータが得られる。
以下の種類がある。
Vision API
画像ラベリング、ランドマークの検出、OCR、不適切コンテンツの発見等。
Video Intelligence API
動画コンテンツへのアノテーション等。
Natural Language API
感情分析、エンティティ分析、構文解析等。
Translation API
翻訳。
Cloud Speech-to-Text API
音声を文字に変換する。
Cloud Text-to-Speech
文字を音声に変換する。
Dialogflow
チャットボットを簡単に作れる。
Cloud Inference API
時系列データの分析。
Recommendations AI
レコメンド。
Media Translation
音声ファイルやストリームの翻訳。
コードレス/最小限の手間で独自のモデルを構築したい
AutoML を使う。
問題のタイプとデータを与えるだけで、簡単にモデルが作れる。 AutoML ならエンドポイントのデプロイまで行える。
ML ワークフローを細かくいじりたい
Vertex AI のカスタムトレーニングを使う。
最も自由度が高い選択肢だが、コードを書く必要があり、機械学習の知識も求められる。
ここまでを表にすると以下のようになる。
| BigQuery ML | Pre-build APIs | AutoML | Custom training | |
|---|---|---|---|---|
| データの種類 | テーブルデータのみ | 色々 | 色々 | 色々 |
| トレーニングデータの規模 | 中から大規模 | 不要 | 小から中規模 | 中から大規模 |
| ML とコードの理解 | 中 | 少ない | 少ない | かなり必要 |
| ハイパーパラメータチューニングの自由度 | 中 | ない | ない | 高い |
| 学習にかかる時間 | 場合による | ない | 場合による | 長い |
データが GCP 外にあって、GCP 上にもってこれない/マルチクラウド環境/エッジ(スマホ上とか)で走らせたい
Kubeflow を使う。 Kubeflow は Kubernates の機械学習ツールキット。これを使うことで、オンプレでもスマホでも同じものを実行することができる。
Kubeflow は以下の利点をっている。
- Composability
- Portability
- Scalability
周辺サービス
前処理やデータストリームの受け取り等、実際に機械学習をする前後のステップで活用できるサービス達。
Pub/Sub
パブリッシャー・サブスクライバーモデルのマネージドサービス。 データストリーム等の取り込み口になる。
Cloud Data Fusion
色々なデータソースからデータを取ってきてどこかに置くパイプラインを作れる。 GUI から作れるのでノーコードソリューション。
Cloud Data Flow
ApacheBeam で記述されたパイプライン処理を動かすためのプラットフォーム。 バッチ処理もストリーム処理も同じコードでできるのが売りだが、コードを書く必要がある。
Flex テンプレートを使う場合、Google が提供する Docker イメージを使ってテンプレートを作成する。 このイメージは実際の Data flow と全く同じなので、ローカルで試したらそのまま Data flow にデプロイできる。
Cloud Data Prep
外れ値の除外や新たな統計量の追加等、データの前処理をレシピとして作成して、Cloud data flow としてエキスポートできる。 ノーコードソリューション。
Vertex AI Pipelines
データの取得、前処理、モデル構築、モデル検証、デプロイまでのワークフローを一気通貫で管理できる。 コードを書く必要がある。
Cloud Data Proc
Hadoop のマネージドサービス。確かにビッグデータの分析に使えるが、これが正解になることはあまり多くない。
Vertex AI ファミリー
Vertex Feature Store
特徴量を一元的に整理して保存する。 複数の機械学習モデルをいろんな部署で別々に作っている場合にとても便利。
Vertex AI Datasets
データセットを一元的に管理できる。
Vertex AI Labeling
トレーニングデータに対するラベル付与を依頼できる。
Vertex Model Monitoring
デプロイ後のモデルの質を継続的に監視できる。 ドリフト検知に使う。
その他の役立ちツール
What-If Tool(WIT)
Google 謹製のデータ可視化・モデル分析ツール。
TensorFlow Extended(TFX)
ML パイプラインを構築して運用するためのオープンソースライブラリ。
Language Interpretability Tool (LIT)
自然言語処理(NLP)モデルを説明し可視化するための OSS。
TensorFlow Probability(TFP)
統計解析と確率のための Python ライブラリで、TPU や GPU で処理できるのが特徴。 伝統的な統計手法も使いたいときに便利。
その他のよくある問題
トレーニングデータセットでは loss が減少し続けているが、テストデータセットで loss が上昇し始めた
過学習が発生している。モデルが複雑すぎるのが原因なので、単純にしてやれば良い。 そのための方策として代表的なものは以下の通り。
- Deep Learning の層を減らす。
- L2 正規化等(L2 regulation)により、過剰な重みに罰則を与える。
大量の特徴量があり、それらの多くが相関している状況で Regression をしたい
多重共線性(multicollinearity)があるデータにどう対応すればよいか。 この場合、通常の Linear regression だと上手く行かないことが多い。
- 部分的最小二乗回帰 (Partial Least Squares Regression)を使う
- この中で主成分分析(Principal Component Analysis)をして特徴量の圧縮が行われる
- 多変量重回帰分析(Multivariate Multiple Regression)を使う
BigQuery ML に含まれないものは何か?
Bigquery ML は SQL の知識さえあれば手軽に使えるが、CI/CD の仕組みは含まれていない。
なので、「自動でデプロイしたい」という文言がある場合は除外される。
大量に特徴量があるのでまずこれを圧縮して学習コストを抑えたいが、情報を失いたくない。
PCA を使う。厳密に言えば PCA を使えば多少の情報が失われるはずだが、これは無視して良い。
BigQuery に格納されているデータを取り出して利用するのに適切な手段は?
- BigQuery Python client library
- ライブラリをインポートするだけで、Python から BQ に対してクエリを叩き、結果を Pandas Dataframe に格納できる。目的にピッタリ。
- BigQuery I/O Connector
- Dataflow (Apache Beam) にデータを BQ から取り出して前処理を行ったりするのに使う。目的にピッタリ。
- tf.data.dataset reader
- TF から BQ のデータを読む時にまず必要になる。
などなどを使う。
Wide/Deep なニューラルネットワークとは?
ニューラルネットワークが Wide であるとは、1 層あたりのノードの数が多いことを表す。 これは学習データの”記憶”に役立つ。
ニューラルネットワークが Deep であるとは、層が多いことを表す。 これは学習の一般化に役立つ。
以下を参照。 Wide & Deep Learning: Better Together with TensorFlow
Tensorflow でデータを読むときには何を使えば良い?
基本的にtf.data.Datasetを使えば OK。
RAM にデータが乗り切らないとかの問題はだいたいこれで解決できる。
Anscombe’s quartet(アンスコムの例)とは?
回帰分析を行ったとき、散布図は異なるのに得られる回帰直線が同じになる場合がある。 これを示すために統計学者アンスコムが紹介した 4 つの例が Anscombe’s quartet。
非線形な関係や外れ値の存在を散布図でちゃんと確かめようね、という教訓を与えてくれる。
TPU を使いたいけどコストを下げたい
Preemptible Cloud TPU を使うと良い。
通常に比べて 7 割引と超安価だが、24 時間で自動的に終了するし、Google 側から勝手に終了されることもある。 要は余り物のリソースを間借りして使えるというサービス。
Vertex AI を使うときにチューニング対象として指定できるハイパーパラメーターは?
num_hidden_layers や learning_rate 等いろいろ。 scaleTier や parameterServerType はインフラの設定なので違う。
Lazy learning って何?
機械学習の種類で、データが入ってきても内部状態を変更せず単にサンプルを蓄積するだけなもの。 予測を実行するときに初めてサンプルを利用する。
例えば K 近傍法やナイーブベイズ。
AI Platform と同じ環境で Tensorflow training job を実行するには?
gcloud ml-engine local train
DNN モデルに説明可能性がほしい!
Integrated Gradient 等を使う。
Tensorflow ではtf.GradientTapeで計算できる。
モデルの学習中に一次保存したい時は?
Pytorch ならsave、Tensorflow ならtrain.CheckpointTFを使う。
ノンパラメトリックな手法とは?
母集団に一切の分布を仮定しない統計解析手法。
K 近傍法や決定木等。 逆に、普通のニューラルネットワークやロジスティック回帰は分布を仮定するのでパラメトリックな手法と呼ばれる。
TensorFlow を使っているけど、Google のサポートを受けたい
TensorFlow Enterprise を使う。 無料だが、GCP のお得意様な大企業にのみ利用可能なことに注意。
BigQuery で、特定のカラムを除外したい
SELECT * EXCEPT (label_column)のように書くと、label_column列以外を得られる。
データ統合サービスの選び方
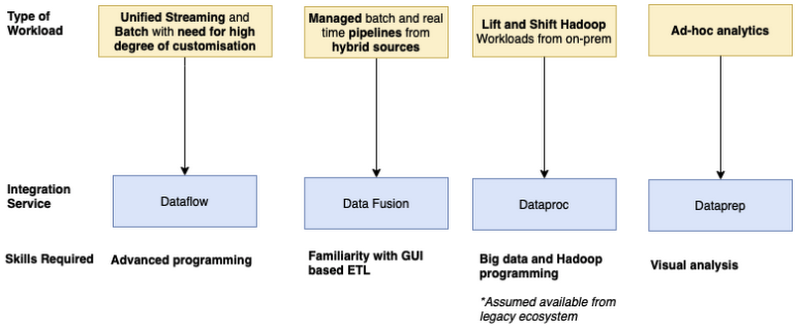
Dataflow
- ストリーム処理もバッチ処理もやりたい
- 細かくカスタマイズしたい
- コードがそこそこ書ける
Data Fusion
- 複数のソースからデータを取得したい
- GUI で操作したい
Dataproc
- オンプレ上に Hadoop でやってた処理をクラウドに持っていきたい
- ビッグデータと Hadoop の知識がある
Data prep
- アドホックな(探索的)分析をしたい
- ノーコードで行ける
一部の情報は古くなっている可能性があります
新しい記事
古い記事

関連するかもしれない記事



